ENGLISH VERSION:
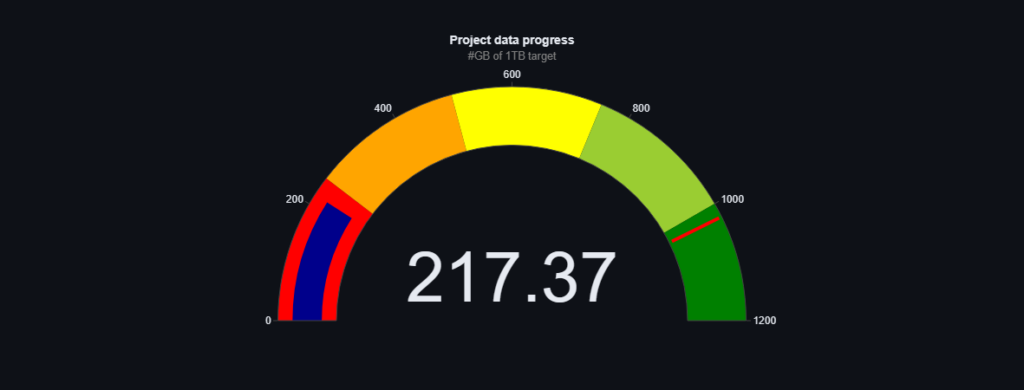
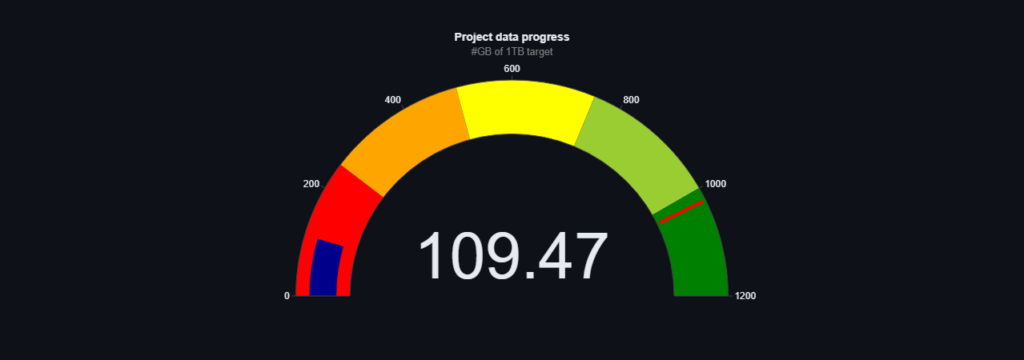
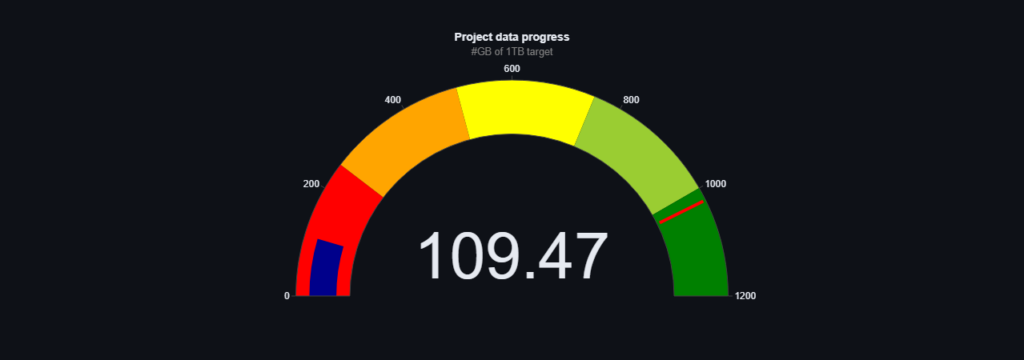
We come with positive news! As promised, we managed to exceed more than 200GB before May. Moreover, currently the counter has stopped at over 217GB, although we are not sure if it has already changed while we are writing this post 🙂
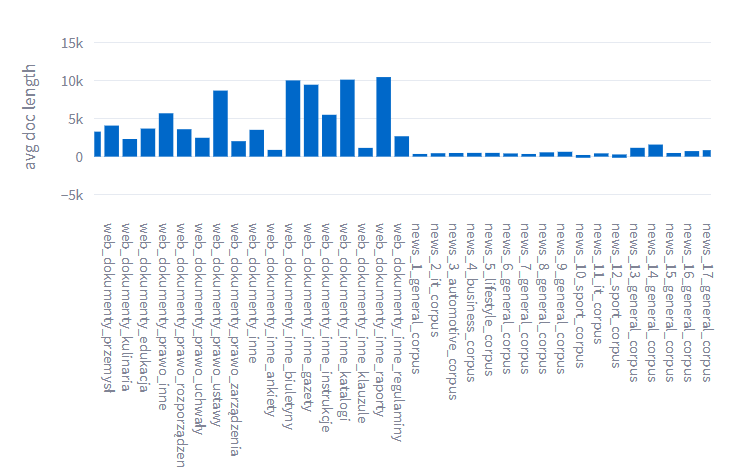
The main source of data acquisition relate to lifestyle and beauty forums.
We can’t describe the enormity of the work and dedication of our experts. Thank you !
As a result, based on the last update of the OSCAR project from 23.01(https://lnkd.in/gEgAQygg)) we surpass the mentioned project in terms of the size of the dataset, by as much as 40%.
We will keep you updated on further changes. We are looking forward to the next news.
Have a productive afternoon 🙂