Today we bring you a summary of a year of activity from the Speakleash project. 🚀
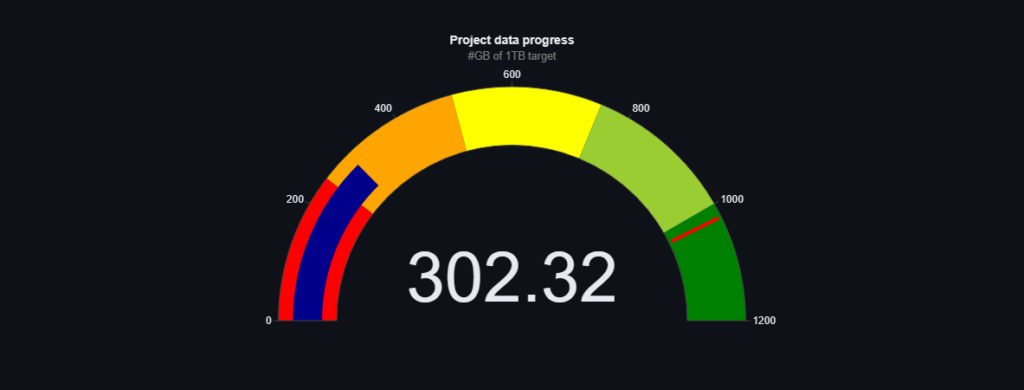
When we set off with the project our goal seemed very far away, some said it was even impossible. 🎯 During this year we have not only formalised our organisation as a foundation, but most importantly we have managed to collect as much as 837.45 GB of data, meaning that we are already very close to the target of 1TB! 💪 It is worth mentioning that we are at the moment creating the world’s largest (or one of the largest) single-language text datasets developed in an open-science model. Additionally, we focus not only on the quantity of data, but also on its quality. All the data we collect is categorised in detail and assessed for quality, you can follow the progress of our work in real time on our dashboard. 🌐
The Speakleash’s work is not only about collecting data, but also about sharing knowledge and inspiring. 💡 This year we have had the pleasure of attending a number of conferences including the Data Science Summit and Data Science Summit Machine Learning Edition, two editions of the Pytech Summit, the CLARIN-PL anniversary conference “Ten years of CLARIN open science infrastructure in Poland” and the Deviniti JIRA DAY Night Talk. 📣 We were partners of events such as ML in PL and Hack To The Rescue. We were a guest on Michal Dulemba‘s Nieliniowy podcast, it is worth noting that an episode featuring us was named the most popular podcast episode of the past year by Crossweb.pl. 🎙
This year has been very important for the development of AI in Poland and the beginning of the work on PLLuM (Polish Large Language Universal Model).
Key units involved in AI in Poland are working on this initiative. We are very curious to see the results!
None of this would be possible if it were not for the hard work of our team, a mix of competences and characters. More than 160 people have already joined the Speakleash Discord (https://discord.gg/NN99d3Uv) and more are constantly joining.👥 Sebastian Kondracki, Maria Filipkowska, PhD, Krzysztof (Chris) Ociepa, Adrian Gwoździej, Paweł Kiszczak, Grzegorz Urbanowicz, Szymon Baczyński, Igor Ciuciura, Pawel Cyrta, Izabela Babis, Waldemar Boszko, Andrzej Cyboroń, Jacek Chwiła are just a small part of our team, it’s impossible to mention them all here.
Thank you all involved for your work and we can’t wait to see what 2024 will bring!🎉