🚀 Chcemy razem z Wami stworzyć największy projekt citizen science dla AI w Europie! 🇪🇺 m.in. z SpeakLeash | Spichlerz (ale nie tylko)!
Bo przełomy w AI to nie tylko nowe architektury i tona GPU. To też nowe podejście do zarządzania danymi, trenowania modeli i tworzenia jakościowych zbiorów. Innowacja to także ludzie – ich wiedza, pasja i zaangażowanie.
📸 Zamiast generować kolejne selfi w stylu bohaterów filmów Studia Ghibli 🐱🚀… zrobisz zdjęcie swojej okolicy, lokalnej potrawy 🍲, zabytku, zwyczaju — i dobrze je opiszesz. To właśnie takich danych potrzebuje polska AI, by rozumieć nasz świat.
Pokażmy Polsce i światu, jak wygląda nasza kultura widziana naszymi oczami! Ale od początku: zerknijcie na naszą prezentację (poniżej) i zobaczcie, jak obecne modele image-text-to-text radzą sobie z opisem polskich potraw.
Spoiler: słabo 😅 A przecież te modele mogą wspierać polski e-commerce, pomagać osobom z niepełnosprawnościami 👁️🗨️ i zwiększać dostępność cyfrową.
🧠 Mamy już modele tekstowe – BIELIK.AI i PLLuM. Dwa duże LLM-y zbudowane w Polsce! Teraz czas na wizję – dosłownie. Model, który rozumie obrazy. I tu wchodzi cały na biało… hashtag#ObywatelBielik 🤍🦅
Będzie to aplikacja webowa i mobilna, w której każdy będzie mógł wrzucać i opisywać zdjęcia. Nie potrzebujemy dzieł sztuki ani selfie – szukamy zdjęć lokalnych potraw, przyrody, tradycji, zabytków.
👉 Chcemy stworzyć:
1️⃣ Największy otwarty zbiór danych obrazów 2️⃣ W całości zbudowany przez obywateli – wspierany przez szkoły, instytucje kultury, lokalne społeczności 🇵🇱 3️⃣ 1 milion zdjęć i opisów w jeden kwartał! 📸
I nie będziemy sami – dołączają do nas duże instytucje 💪 (o szczegółach już niedługo – trwają podpisy 👀).
🚀 Dołącz do przełomowego projektu AI 🚀 Twoja cegiełka może zmienić świat!
Mamy dla Was coś wyjątkowego! Chcemy Was zaprosić do globalnej inicjatywy, która ma realny wpływ na bezpieczeństwo w sieci. To projekt, w którym każdy może pomóc budować AI chroniące nasze dzieci, młodzież i społeczeństwo przed toksycznymi treściami. Brzmi ciekawie? No to czytajcie dalej!
Jednym z takich projektów będzie hashtag#ObywatelBielik (już za chwilę o nim usłyszycie!). Ale zanim do tego dojdziemy – mamy dla Was mega ważne wyzwanie!
💡 Czy kiedykolwiek zetknęliście się w sieci z hejtem, wulgaryzmami, nawoływaniem do przemocy? A może z niepokojącymi treściami w chatbotach, które powinny wspierać, a zamiast tego szkodzą? To ogromny problem, zwłaszcza dla młodych ludzi. Ich zdrowie psychiczne jest dziś na krawędzi – coraz częściej szukają wsparcia u AI, traktując ją jak wirtualnego przyjaciela. Ale co, jeśli zamiast pomocy dostaną toksyczne treści?
🛡️ Tworzymy model AI-strażnika („guardrails”), który pomoże wykrywać i eliminować zagrożenia. Może być wykorzystany do:
✅ moderacji komentarzy i wykrywania hejtu ✅ analizowania czatów pod kątem szkodliwych intencji ✅ filtrowania i poprawiania odpowiedzi AI, by unikać toksycznych treści ✅ ochrony użytkowników przed niebezpiecznymi treściami
Wynik? Udostępniliśmy ankietę i w kilka godzin mieliśmy 5831 odpowiedzi, a w kilka dni 20 000! 🚀
🔥 Ale to wciąż za mało! 🔥
W kursie hashtag#UmiejętnościJutraAI (pozdrawiamy Karol Stryja, Cezary Jaroni) organizowanym przez Google i SGH Warsaw School of Economics uczestniczyło 20 000 osób, większość zrobiła test z 50 pytaniami. FANTASTYCZNIE!. A co, gdyby wszyscy zrobili dodatkową „pracę dyplomową” – ocenili 10-20 treści w naszej ankiecie? To już 200 000 – 400 000 odpowiedzi! A jakby 50? MILION! 💥
To byłby game-changer – globalny dataset, który posłużyłby naukowcom do tworzenia lepszych, bardziej bezpiecznych modeli AI.
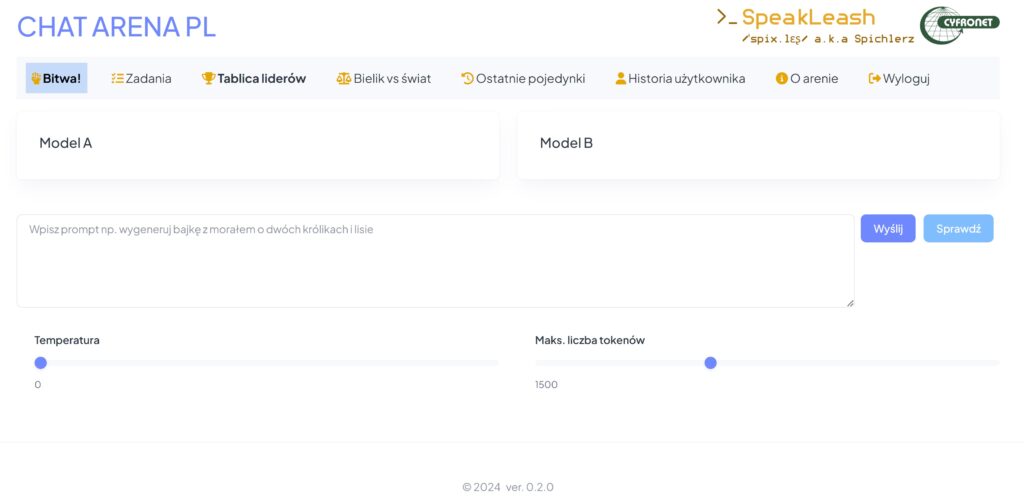
Na początku czerwca udostępniliśmy narzędzie CHAT ARENA PL. Jest to „pole bitwy” dużych modeli językowych, na którym możemy porównywać ich umiejętności w odpowiadaniu na zadane przez Was pytania/prompty.
Do momentu publikacji tego posta, 332 użytkowników naszej CHAT Areny rozegrało 5270 bitew. Liczymy jednak na znacznie więcej! Każdy pomysł na weryfikację jakości modeli się liczy. Dołącz do nas i pomóż w testach LLM-ów. Nie musisz być specjalistą od AI. Wystarczą dobre chęci, ciekawe prompty i rzetelna ocena wyników!
CHAT ARENA PL – Jak to działa?
Wpisywanie promptów: Użytkownicy zaczynają od wpisania promptu, czyli pytania lub zadania dla modelu LLM.
Generowanie odpowiedzi: System tworzy odpowiedzi z dwóch modeli AI na podstawie podanego promptu.
Ocena odpowiedzi: Użytkownicy oceniają, która odpowiedź jest lepsza. Po dokonaniu oceny odpowiedzi przez użytkownika system ujawnia użyte modele LLM.
Zapis promptów: Wszystkie prompty są zapisywane do późniejszej analizy i poprawy przyszłych wersji modeli LLM.
Na start dostępnych jest 7 modeli do testowania, w tym Llama3 Meta, Mixtral Mistral AI, Bielik SpeakLeash.org oraz GPT-3.5 OpenAI.
Każdy z modeli, który bierze udział w konfrontacji, jest pozycjonowany w naszym rankingu ELO. Pozwoli to w miarodajny sposób zestawić modele względem siebie dla zadań w języku polskim. Ocena jest wystawiana przez użytkowników, a nie syntetyczne/automatyczne benchmarki, które nie zawsze muszą odzwierciedlać możliwości danych modeli w realnych zastosowaniach.
CHAT ARENA PL – DOSTĘPNE FUNKCJE:
Zakładka Bitwa!– czyli właściwa arena modeli LLM. Ty tu rządzisz! Podajesz prompt, modele LLM generują swoje odpowiedzi, ty oceniasz która odpowiedź jest lepsza. Dla zwiększenia obiektywności przed wydaniem oceny nie wiesz który model wygenerował którą odpowiedź.
Zakładka Zadania– przykładowe prompty dla inspiracji, jeżeli nie wiesz od czego rozpocząć.
Zakładka Bielik vs świat możliwość porównania jakości generowanych tekstów przez nasz model Bielik.AI (Bielik-2 11B) vs modele z całego świata
SPEAKLEASH CHAT ARENA PL
ROZWÓJ KOMPETENCJI AI W POLSCE
Wszystkie wprowadzone prompty są zapisywane w celach analitycznych i poprawy jakości przyszłych modeli LLM. Nie zbieramy żadnych danych osobowych do działań marketingowych czy też promocyjnych. Jedyne dane osobowe które gromadzimy, zbierane są w celu zapewnienia bezpieczeństwa aplikacji, danych i zapobiegania nadużyciom.
Przy korzystaniu z CHAT ARENY prosimy o kulturę, profesjonalne prompty oraz ich rzetelne oceny. Przyczyni się to do rozwoju i doskonalenia polskich modeli językowych.
Pragniemy lepiej zrozumieć, jak duże modele językowe są wykorzystywane w praktyce przez profesjonalistów z różnych sektorów biznesu i nauki.
🦸 Dlaczego Twoja opinia jest dla nas ważna?
Liczymy, iż dowiemy się, w jaki sposób LLMy zmieniają krajobraz biznesowy, w których obszarach znajdują największe zastosowanie, oraz jakie są oczekiwania wobec przyszłych innowacji.
🎈 Spodziewane korzyści z badania
Twoje odpowiedzi pomogą nam zidentyfikować kluczowe tendencje, potrzeby oraz możliwości związane z zastosowaniem LLM.
Ostatecznym celem jest lepsze zrozumienie, jak możemy wspierać biznes i naukę w wykorzystywaniu tych technologii dla maksymalizacji wartości i innowacyjności.
Niektórzy mówili, że to niemożliwe albo z ironią życzyli nam powodzenia. Wiele osób jednak kibicowało temu przedsięwzięciu i po nieco ponad roku pomysłodawca pierwszego polskiego i otwartego projektu open-source/open-science może patrzeć z dumą na efekty i dziękować wszystkim za początkową dawkę motywacji. Bez budżetu, rozdmuchanego marketingu czy sponsorów, za to z wielkimi ambicjami, poświęceniem wolnego czasu, często też kosztem snu czy innych prywatnych aktywności. Polski zespół entuzjastów z projektu SpeakLeash aka Spichlerz właśnie opublikował swój pierwszy duży model językowy o nazwie Bielik-7B-v0.1. Czy sprawi, że odlecimy z zachwytu czy jednak czeka ich lot Ikara?
Zdjęcie: część zespołu SpeakLeash z pracownikami AGH Cyfronet przy superkomputerze Helios (źródło własne SpeakLeash)
SpeakLeash to inicjatywa open-science, która zaczęła działać ponad półtora roku temu, stawiając sobie za cel stworzenie największego polskiego zbioru danych tekstowych oraz opracowanie otwartego dużego modelu językowego (ang. large language model, w skrócie LLM). W skład zespołu projektowego wchodzą przede wszystkim pracownicy polskich przedsiębiorstw, badacze z ośrodków naukowych oraz studenci kierunków związanych z obszarami sztucznej inteligencji. Zaangażowanie członków projektu, którzy poświęcają swój prywatny czas i umiejętności pro bono służy nie tylko realizacji wspomnianego zadania, lecz także tworzeniu społeczności oraz – przede wszystkim – rozwojowi ekosystemu służącego budowie zaawansowanych modeli językowych (a wkrótce może również multimodalnych, czyli analizujących więcej niż jedno źródło informacji, np.: tekst i zdjęcia).
Rok 2024 dla SpeakLeash zaczął się spektakularnie, bo w styczniu ogłosili zebranie 1 TB danych, a więc udało im się już osiągnąć główny cel projektu. Co ważne, zebrane dane są opisane i przygotowane pod kątem AI ACT – nowej dyrektywy unijnej regulującej sprawy związane z uczeniem maszynowym, sztuczną inteligencją oraz użyciem danych do treningu modeli. Tym samym SpeakLeash stał się największym, najlepiej opisanym i udokumentowanym zbiorem danych w języku polskim.
Niemalże równocześnie pojawił się model APT3-1B-Base oraz APT3-1B-Instruct, który został w większości wytrenowany na danych pochodzących z zasobów Spichlerza. Model wytrenowany został na konsumenckiej karcie graficznej, przez co trening trwał prawie półtora miesiąca (dokładnie były to 44 dni ciągłego przetwarzania 285 GB danych treningowych). Pomimo relatywnie niewielkiego rozmiaru modelu (1B, czyli 1 miliard parametrów), potrafi on odpowiadać w języku polskim, ale członkowie projektu mieli większe ambicje.
SpeakLeash był znany już wcześniej w środowisku, ponieważ współpracował z ośrodkami naukowymi zajmującymi się przetwarzaniem języka naturalnego, takimi jak Clarin, PAN IPI czy też NASK PIB. Jednak zebranie tak dużej liczby danych oraz wytrenowanie modelu APT3-1B pokazało determinację tej grupy badaczy i entuzjastów. Jednocześnie wysłali jasny sygnał, że mają chęć na więcej i nie jest to ich ostatnie słowo w kontekście dużych modeli językowych.
Kamieniem milowym okazało się rozpoczęcie ścisłej współpracy SpeakLeash – Akademickie Centrum Komputerowe Cyfronet AGH. Cyfronet jest polskim centrum superkomputerowym i ostatnim brakującym elementem w układance. Jako pierwszy komercyjny odbiorca na świecie najnowszych akceleratorów graficznych (ang. GPU) GH200 produkcji NVidii są w stanie zaproponować niespotykaną na polskiej ziemi moc obliczeniową szacowaną na 35 petaflopów. Superkomputery Athena oraz Helios, notowane na liście TOP500, od ponad miesiąca wspomagają Spichlerz w tworzeniu, eksperymentowaniu oraz testowaniu LLM-ów.
Dziś przychodzimy do Was z podsumowaniem roku działalności projektu Speakleash. 🚀
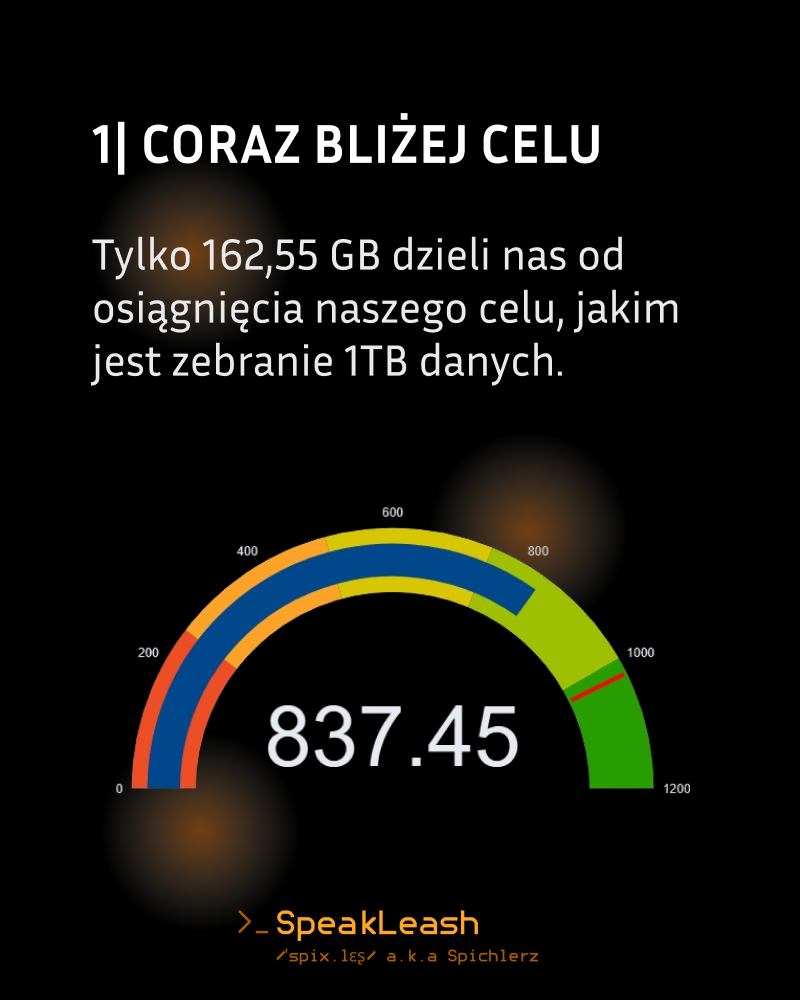
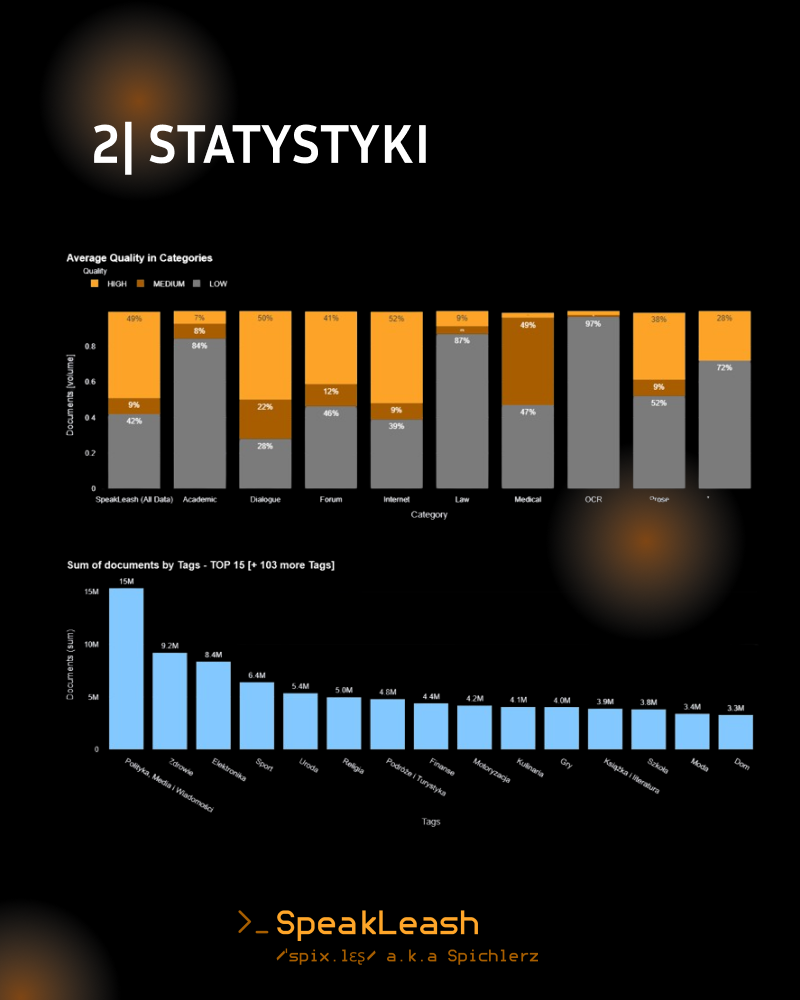
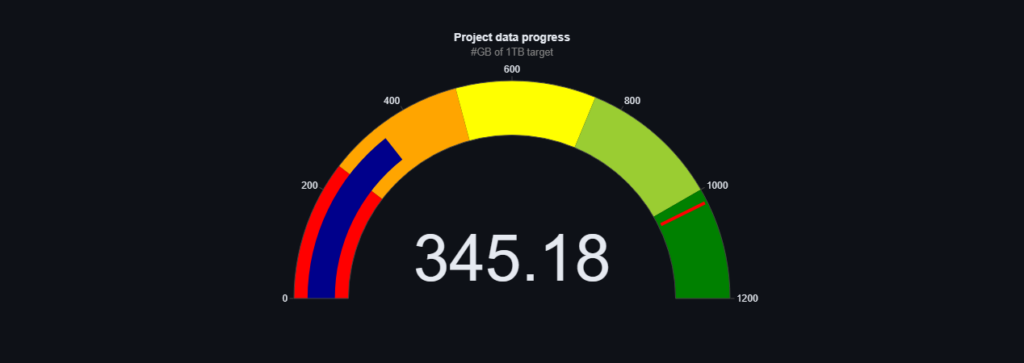
Kiedy ruszyliśmy z projektem nasz celu wydawał się bardzo odległy, niektórzy twierdzili, że wręcz niemożliwy. 🎯 Przez ten rok nie tylko sformalizowaliśmy naszą organizację jako fundację, ale przede wszystkim udało nam się zebrać aż 837,45 GBdanych, znaczy to, że jesteśmy już bardzo blisko docelowego 1TB! 💪 Warto zaznaczyć, że tworzymy w tym momencie największy na świecie (lub jeden z największych) zestawów danych tekstowych w jednym języku rozwijany w modelu open-science. Dodatkowo stawiamy nie tylko na ilość danych, ale też na ich jakość. Wszystkie zebrane przez nas dane są szczegółowo kategoryzowane i oceniane pod względem jakości, postępy naszych prac śledzić możecie na bieżąco na naszym dashboardzie. 🌐
Działalność Spichlerza to nie tylko zbieranie danych, ale też dzielenie się wiedzą i inspirowanie. 💡 W tym roku mieliśmy przyjemność wziąć udział w wielu konferencjach m.in. Data Science Summit oraz Data Science Summit Machine Learning Edition, dwóch edycjach Pytech Summit, konferencji jubileuszowej CLARIN-PL “Dziesięć lat otwartej infrastruktury naukowej CLARIN w Polsce” oraz Deviniti JIRA DAY Night Talk. 📣 Byliśmy partnerami wydarzeń takich jak ML in PL czy Hack To The Rescue. Gościliśmy w podcaście Nieliniowy Michal Dulemba, warto zaznaczyć, że odcinek z naszym udziałem określony został przez Crossweb.pl najpopularniejszym odcinkiem podcastu minionego roku. 🎙
Ten rok był bardzo ważny dla rozwoju AI w Polsce i rozpoczęcia prac nad PLLuM (Polish Large Language Universal Model). Nad tą inicjatywą pracują kluczowe jednostki zajmujące się AI w Polsce. Jesteśmy bardzo ciekawi efektów!
Speakleash - największy dataset tekstów w języku polskim
Od ostatniej aktualizacji, którą chwaliliśmy się 6 września, dataset tekstów w języku polskim nad którym pracuje Spichlerz znacznie się rozrósł. Obecnie baza tekstów osiągnęła imponujący rozmiar 833.36 GB, co oznacza wzrost o ponad 470 GB w ciągu zaledwie 3.5 miesiąca.
Najważniejsze zmiany obejmują:
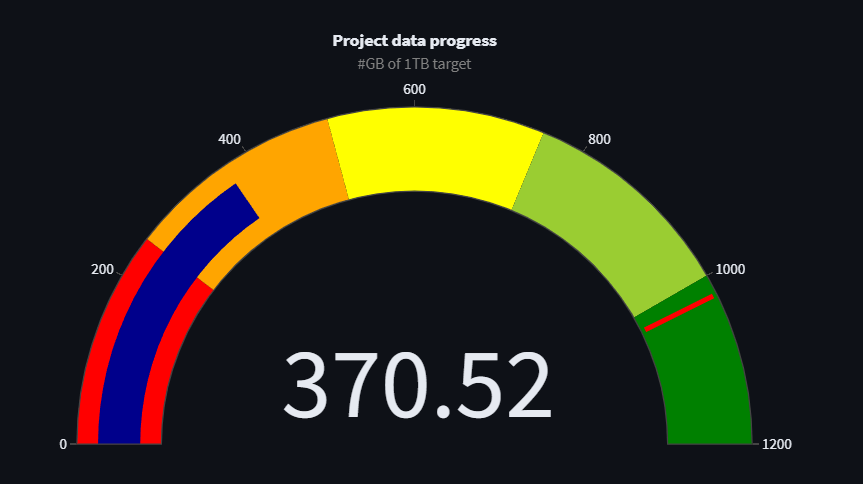
Wzrost bazy tekstów: Rozmiar Spichlerzowego datasetu wzrósł z 370 GB na imponujące 833.36 GB. To znaczące zwiększenie ilości zgromadzonych danych świadczy o intensyfikacji działań projektu w obszarze zbierania i analizy polskich tekstów.
Przebicie wielkości datasetu The Pile: Speakleash przebił pod względem rozmiaru datasetu znany projekt The Pile, potwierdzając pozycję projektu jako jednego z największych źródeł danych tekstowych na świecie i z pewnością największego dla języka polskiego.
Nowe dane z forów internetowych: Do naszej bazy dodanych zostało ponad 100 GB treści pochodzących głównie z różnych forów internetowych.
Dane z datasetu CulturaX: wprowadziliśmy nowe dane z datasetu CulturaX, które zostały poddane szczegółowej analizie metrykami Speakleasha. Dodatkowo, dane zostały precyzyjnie skategoryzowane, co zwiększa ich użyteczność i wartość analityczną.
Zebranie 370GB w tak krótkim czasie świadczy o niesamowitym zaangażowaniu i wysokim tempie pracy osób wspierających rozwój projektu. Nie zamierzamy się zatrzymywać!
Jeżeli chcesz pomóc w osiągnięciu naszego podstawowego celu czyli zebrania 1TB polskich danych tekstowych to zapraszamy do współpracy!
🚀 Już w ten czwartek (7 grudnia) na Pytech Summit (https://pytechsummit.pl/) będziecie mieli przyjemność posłuchać reprezentacji zespołu Spichlerz, w składzie Szymon Baczyński i Igor Ciuciura. 🎙️
Prelekcja dotyczyć będzie tworzenia pakietu Speakleash jako narzędzia obsługi danych.
Konferencja odbywa się w trybie online. Zarezerwuj swój bilet już dziś! 🎟️
Od czasu ostatniej aktualizacji Spichlerzowego datasetu, zasoby tekstowe powiększyły się o kolejne 25 GB i tym samym przekroczyliśmy granicę 370 GB zgromadzonych danych.
Najnowsze informacje pochodzą z różnych źródeł internetowych, obejmujących szeroki zakres kategorii, od turystyki po informacje dotyczące gier komputerowych i usług internetowych. Dodatkowo, systematycznie uzupełniamy naszą bazę o treści pochodzące z różnych forów internetowych.
Trwają także końcowe prace nad nową wersją projektowego dashboardu prezentującego dane na temat datasetu. Nowa wersja będzie znacznie ulepszona pod kątem możliwości filtracji danych, wyglądu i wydajności. Stay tuned!
Chcielibyśmy podzielić się z Wami najnowszymi aktualizacjami dotyczącymi naszych danych treningowych. Od ostatniej aktualizacji udało nam się pozyskać imponujące 28GB nowych danych, które będą miały ogromne znaczenie dla rozwoju naszego modelu.
Wśród tych danych szczególną uwagę warto zwrócić na rozbudowaną technologię OCR, która umożliwia analizę tekstu zawartego na obrazach.
Ponadto udało nam się zdobyć znaczną ilość danych z kategorii motoryzacji oraz o tematyce sportowej. To niewątpliwie poszerzy nasze możliwości szkolenia modelu i umożliwi mu lepsze zrozumienie tych dziedzin.
W ramach tych aktualizacji wprowadziliśmy również nowe metryki oceny jakości poszczególnych tekstów oraz całych paczek danych. Każdy tekst jest teraz oznaczany jako high, med lub low w zależności od jego jakości. To pomoże nam lepiej zrozumieć i selekcjonować wartościowe informacje.
Dział inżynierii lingwistycznej pod wodzą Maria Filipkowska, PhD Filipkowska działa w pełnym wymiarze czasu i jest niezmiernie zaangażowany w rozwijanie naszych zasobów. Dzięki ich wysiłkom, nasz zespół jest gotowy, by dostarczyć Wam jeszcze lepsze dane treningowe.
Dziękujemy Wam za cenne uwagi i wsparcie, które pomagają nam w rozwoju Speakleash. Pracujemy ciężko, aby dostarczyć Wam jak najlepsze doświadczenia i informacje.
Zapraszamy do dalszego korzystania z naszych zasobów i życzymy Wam wspaniałego dnia!