W najbliższe dni życzymy Wam dużo spokoju i radości!
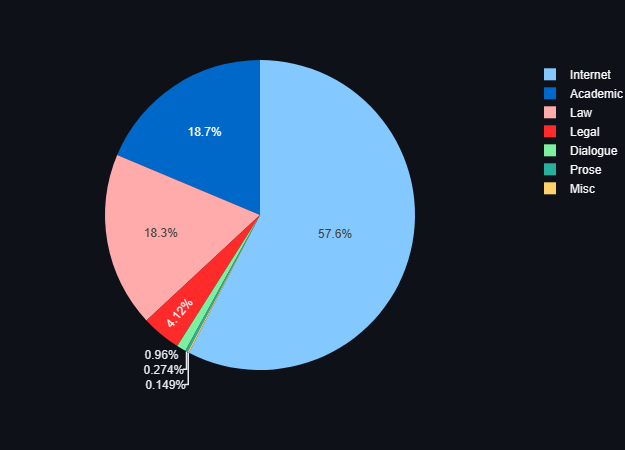
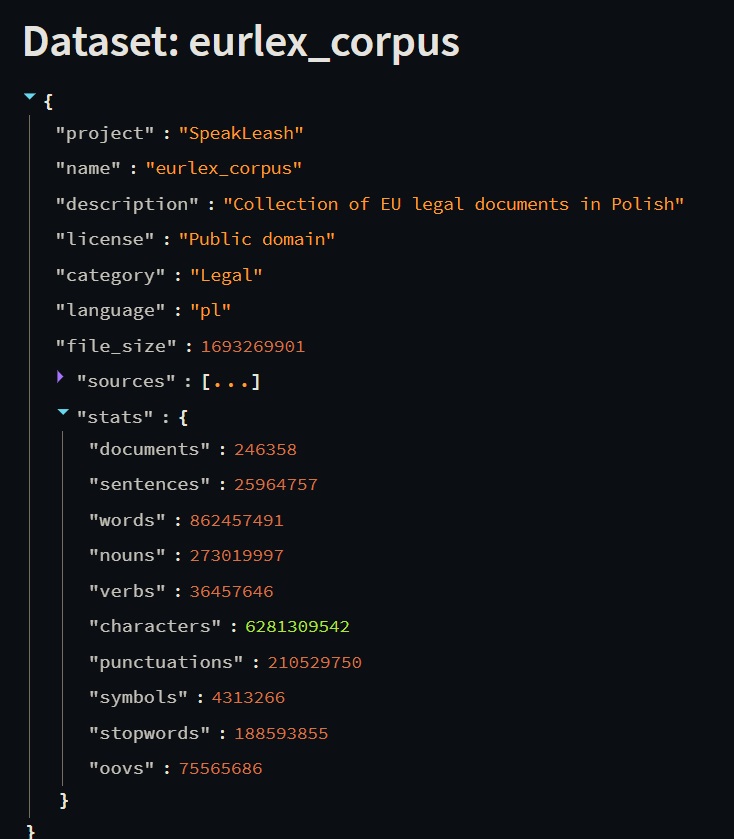
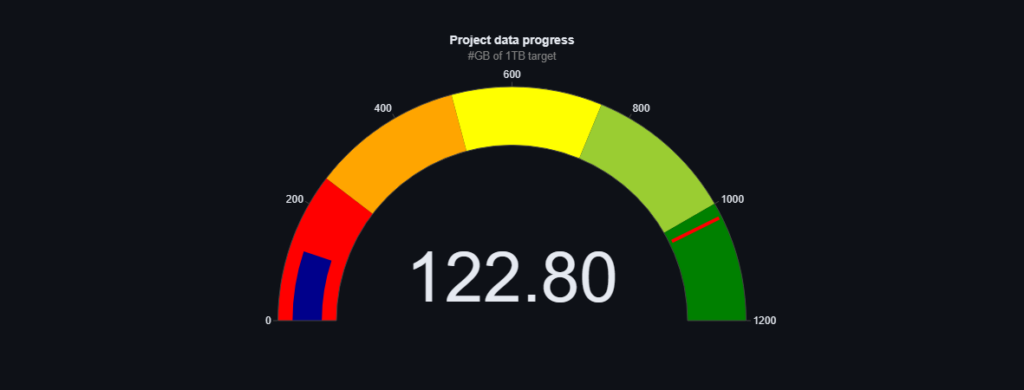
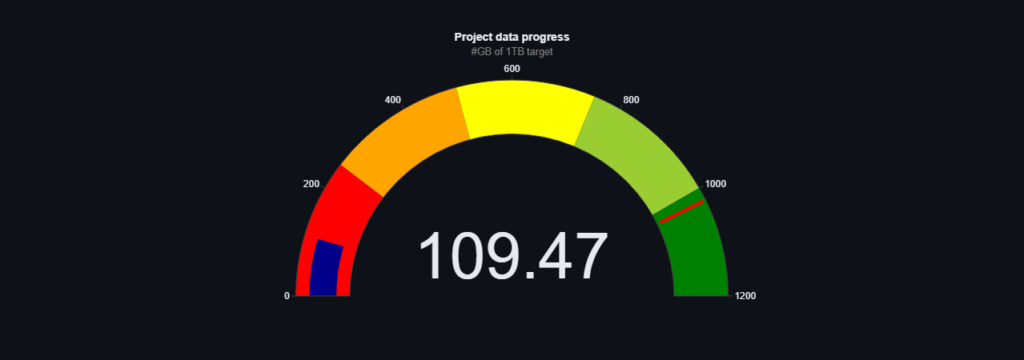
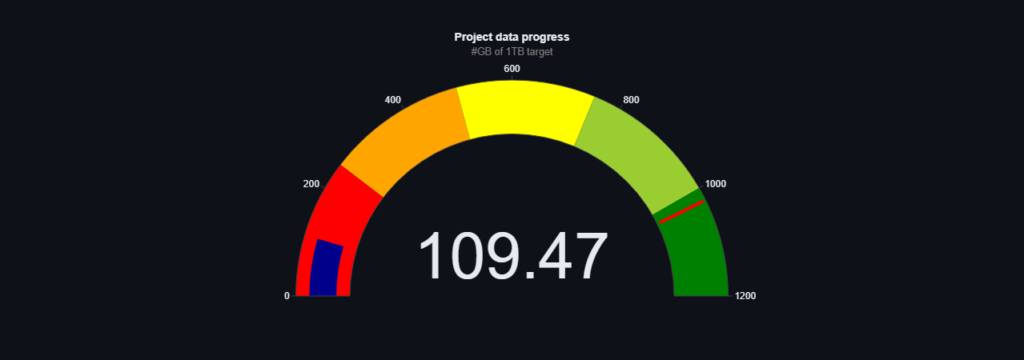
My tymczasem raportujemy o zaimportowaniu kolejnych danych. Jak obiecaliśmy kolejne z kategorii blogi i edukacja co wraz z wcześniejszymi tekstami daję nam ponad 145 GB danych tekstowych. Więcej szczegółów możecie zobaczyć na naszym dashboradzie: Speakleash Dashboard · Streamlit
Wesołego jajka!