Nowy tydzień, nowa aktualizacja!
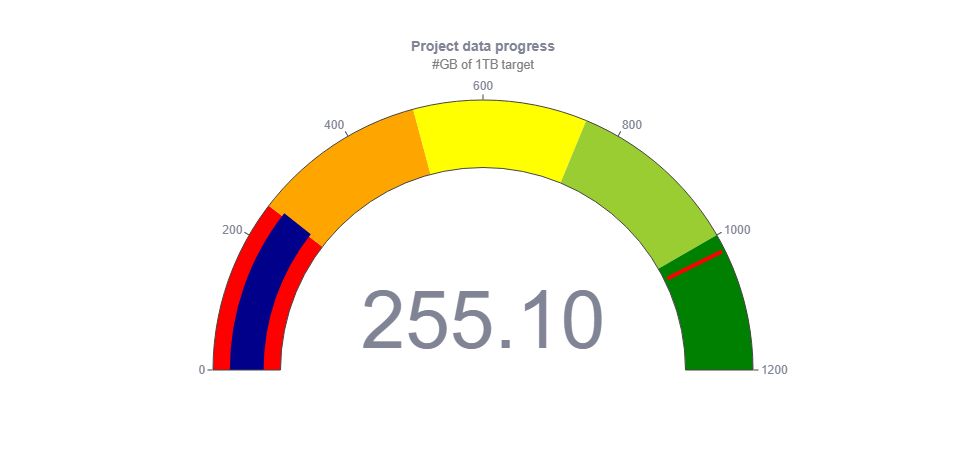
Tym razem przekraczamy magiczną liczbę oznaczającą realizację ćwiartki naszego celu. 255.1 GB lub 255 100MB(co brzmi jeszcze bardziej imponująco) to dokładna pojemność danych tekstowych w języku polskich jaką udało nam się do tej pory zebrać. Zebrane dane, podobnie jak ostatnio, dotyczyły kategorii fora i edukacja.
Znając naszych badaczy, za tydzień będziemy jeszcze bliżej celu, bo tempo zbierania danych rośnie wręcz wykładniczo. Jest to zasługa również osób które w ostatnich tygodniach dołączyły do projektu zainspirowanych pomysłem, aby wspomóc naszą pracę.
Jeśli jesteś zainteresowany być częścią czegoś wielkiego, napisz do nas!!
Link do kontaktu w komentarzu. 👇