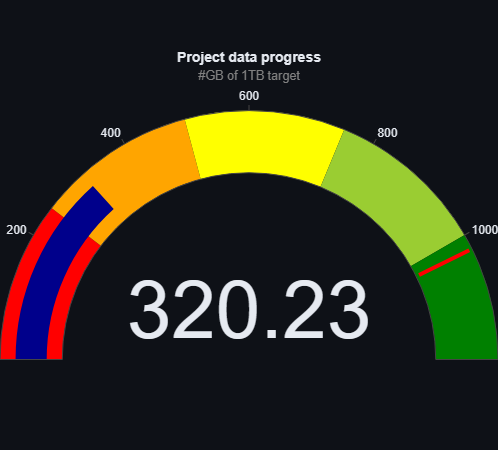
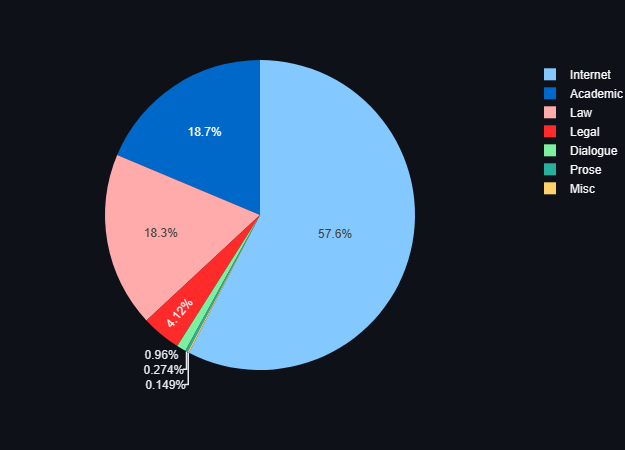
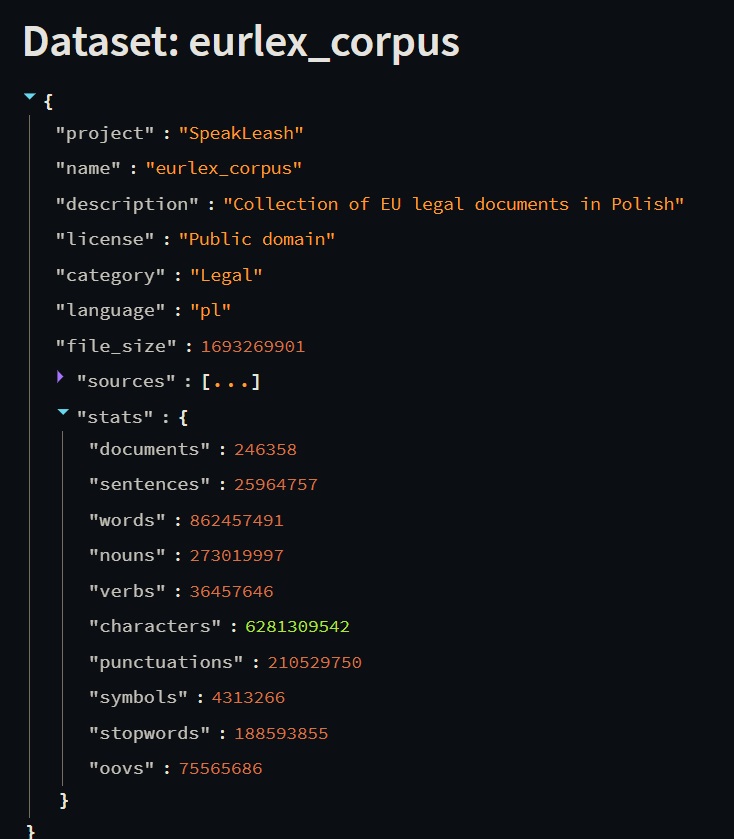
Mamy przyjemność poinformować, że nasz projekt Speakleash właśnie doczekał się ważnej aktualizacji danych – teraz dysponujemy aż 320GB materiałów!
W ramach tej aktualizacji dodaliśmy kilka istotnych zmian. Najważniejsza z nich to wprowadzenie nowych metryk oceniających jakość tekstu. Te metryki, teraz będą integralną częścią naszych datasetów, pozwalając na jeszcze precyzyjniejszą analizę i interpretację wyników.
Co więcej, poszerzyliśmy naszą bazę danych o kilka nowych zestawów danych. Wśród nich znajdą się między innymi artykuły sportowe, a także imponująca paczka kilkuset tysięcy plików przetworzonych za pomocą technologii OCR.
Na koniec warto wspomnieć, że kontynuujemy również pracę nad przygotowywaniem datasetów z for internetowych. Wierzymy, że te unikalne i różnorodne źródła danych przyczynią się do jeszcze lepszego zrozumienia i modelowania języka naturalnego.
Dziękujemy za wasze ciągłe wsparcie i zaangażowanie w projekt Speakleash! Jesteśmy podekscytowani tymi zmianami i nie możemy się doczekać, aby zobaczyć, jakie nowe możliwości przyniosą one dla naszej społeczności.
#speakleash #AI #NLP #BigData