Witajcie Speakleashers!
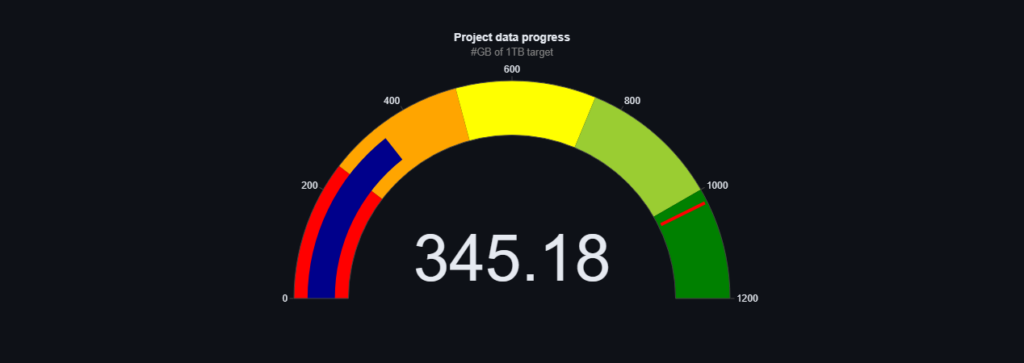
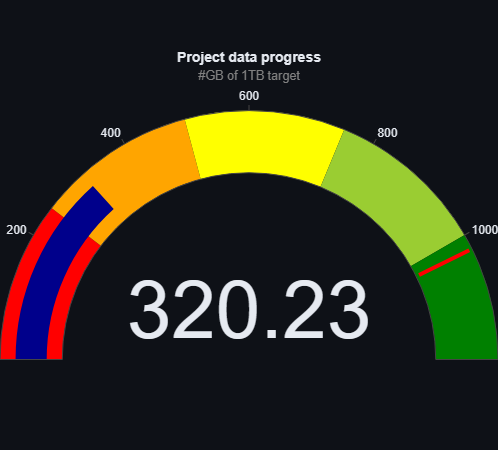
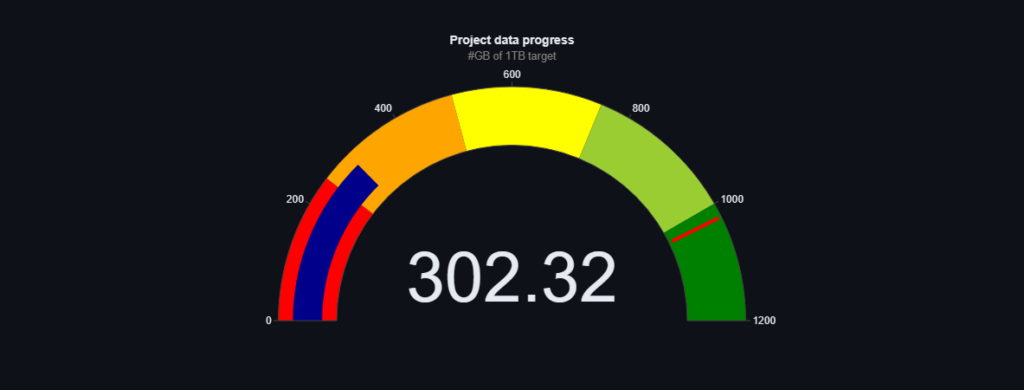
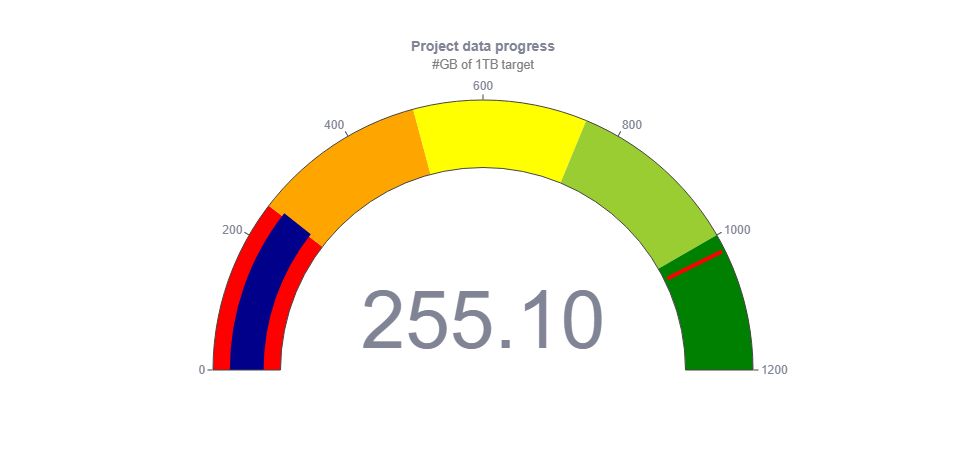
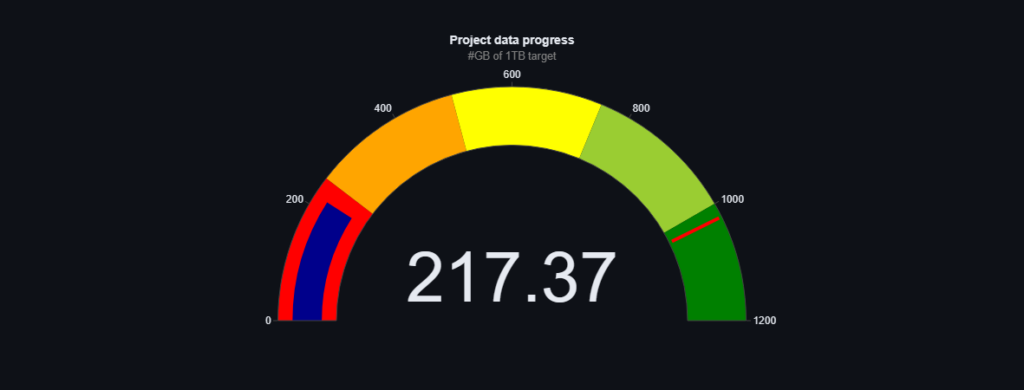
Chcielibyśmy podzielić się z Wami najnowszymi aktualizacjami dotyczącymi naszych danych treningowych. Od ostatniej aktualizacji udało nam się pozyskać imponujące 28GB nowych danych, które będą miały ogromne znaczenie dla rozwoju naszego modelu.
Wśród tych danych szczególną uwagę warto zwrócić na rozbudowaną technologię OCR, która umożliwia analizę tekstu zawartego na obrazach.
Ponadto udało nam się zdobyć znaczną ilość danych z kategorii motoryzacji oraz o tematyce sportowej. To niewątpliwie poszerzy nasze możliwości szkolenia modelu i umożliwi mu lepsze zrozumienie tych dziedzin.
W ramach tych aktualizacji wprowadziliśmy również nowe metryki oceny jakości poszczególnych tekstów oraz całych paczek danych. Każdy tekst jest teraz oznaczany jako high, med lub low w zależności od jego jakości. To pomoże nam lepiej zrozumieć i selekcjonować wartościowe informacje.
Dział inżynierii lingwistycznej pod wodzą Maria Filipkowska, PhD Filipkowska działa w pełnym wymiarze czasu i jest niezmiernie zaangażowany w rozwijanie naszych zasobów. Dzięki ich wysiłkom, nasz zespół jest gotowy, by dostarczyć Wam jeszcze lepsze dane treningowe.
Dziękujemy Wam za cenne uwagi i wsparcie, które pomagają nam w rozwoju Speakleash. Pracujemy ciężko, aby dostarczyć Wam jak najlepsze doświadczenia i informacje.
Zapraszamy do dalszego korzystania z naszych zasobów i życzymy Wam wspaniałego dnia!
#data #nlp #speakleash #datasets