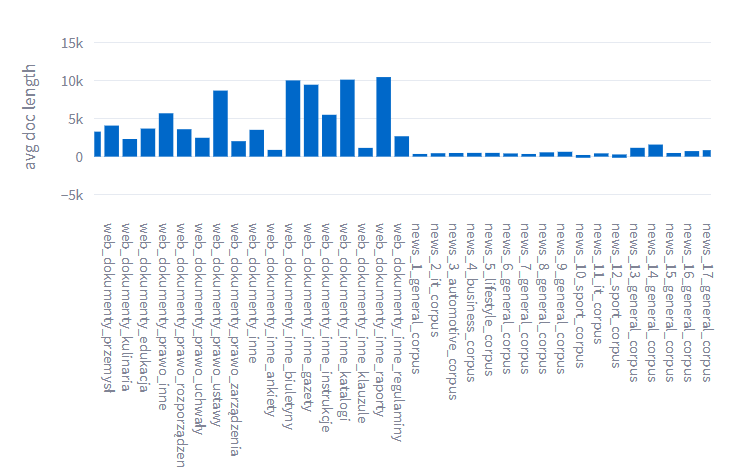
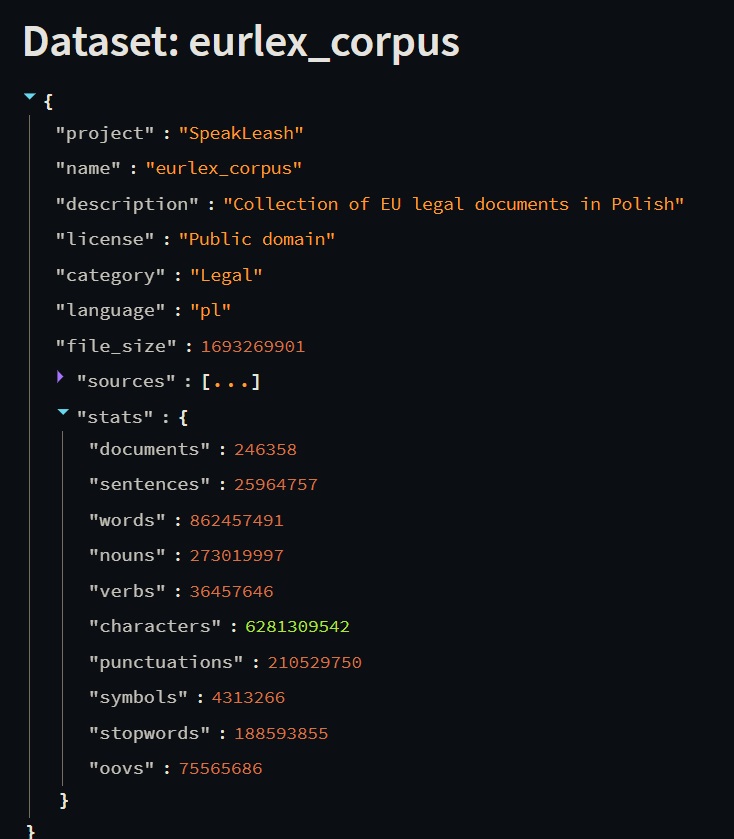
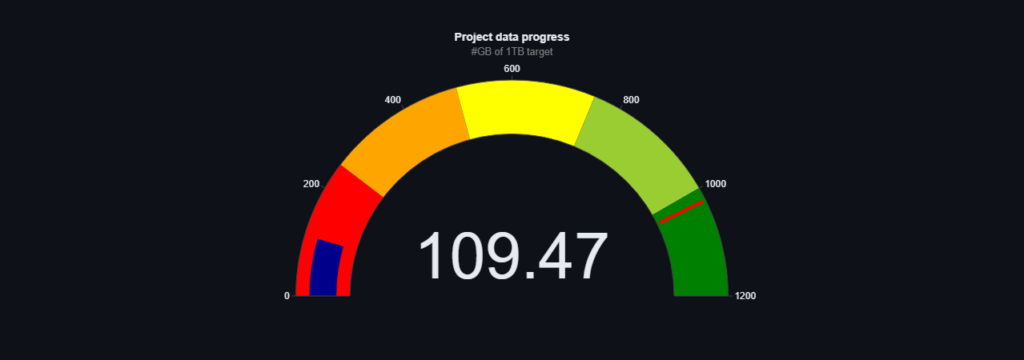
As promised, more data from the blogs and education category is now in our granary! To get an idea of the task we’re facing, the data from this category alone is 2.9million files and that’s just a fraction of what we’ve collected. Another added set of data relates to job listings. As a result, at the moment our project has the largest number of Polish data!