
Na początku czerwca udostępniliśmy narzędzie CHAT ARENA PL. Jest to „pole bitwy” dużych modeli językowych, na którym możemy porównywać ich umiejętności w odpowiadaniu na zadane przez Was pytania/prompty.
Do momentu publikacji tego posta, 332 użytkowników naszej CHAT Areny rozegrało 5270 bitew. Liczymy jednak na znacznie więcej! Każdy pomysł na weryfikację jakości modeli się liczy. Dołącz do nas i pomóż w testach LLM-ów. Nie musisz być specjalistą od AI. Wystarczą dobre chęci, ciekawe prompty i rzetelna ocena wyników!
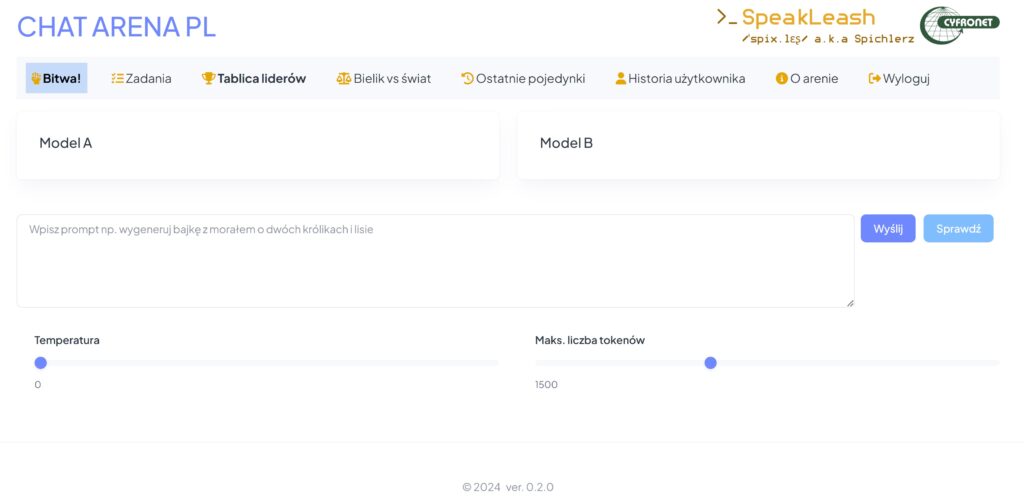
CHAT ARENA PL – Jak to działa?
- Wpisywanie promptów: Użytkownicy zaczynają od wpisania promptu, czyli pytania lub zadania dla modelu LLM.
- Generowanie odpowiedzi: System tworzy odpowiedzi z dwóch modeli AI na podstawie podanego promptu.
- Ocena odpowiedzi: Użytkownicy oceniają, która odpowiedź jest lepsza. Po dokonaniu oceny odpowiedzi przez użytkownika system ujawnia użyte modele LLM.
- Zapis promptów: Wszystkie prompty są zapisywane do późniejszej analizy i poprawy przyszłych wersji modeli LLM.
Na start dostępnych jest 7 modeli do testowania, w tym Llama3 Meta, Mixtral Mistral AI, Bielik SpeakLeash.org oraz GPT-3.5 OpenAI.
Każdy z modeli, który bierze udział w konfrontacji, jest pozycjonowany w naszym rankingu ELO. Pozwoli to w miarodajny sposób zestawić modele względem siebie dla zadań w języku polskim. Ocena jest wystawiana przez użytkowników, a nie syntetyczne/automatyczne benchmarki, które nie zawsze muszą odzwierciedlać możliwości danych modeli w realnych zastosowaniach.
CHAT ARENA PL – DOSTĘPNE FUNKCJE:
- Zakładka Bitwa! – czyli właściwa arena modeli LLM. Ty tu rządzisz! Podajesz prompt, modele LLM generują swoje odpowiedzi, ty oceniasz która odpowiedź jest lepsza. Dla zwiększenia obiektywności przed wydaniem oceny nie wiesz który model wygenerował którą odpowiedź.
- Zakładka Zadania – przykładowe prompty dla inspiracji, jeżeli nie wiesz od czego rozpocząć.
- Zakładka Tablica liderów – ranking ELO (Speakleash/Bielik-7B-Instruct-v0.1, GPT-3.5-Turbo, Mixtral-8x7b-32768, Llama3-70b-8192, Llama3-8b-8192, Gemma-7b-it).
- Zakładka Bielik vs świat możliwość porównania jakości generowanych tekstów przez nasz model Bielik.AI (Bielik-2 11B) vs modele z całego świata
ROZWÓJ KOMPETENCJI AI W POLSCE
Wszystkie wprowadzone prompty są zapisywane w celach analitycznych i poprawy jakości przyszłych modeli LLM. Nie zbieramy żadnych danych osobowych do działań marketingowych czy też promocyjnych. Jedyne dane osobowe które gromadzimy, zbierane są w celu zapewnienia bezpieczeństwa aplikacji, danych i zapobiegania nadużyciom.
Przy korzystaniu z CHAT ARENY prosimy o kulturę, profesjonalne prompty oraz ich rzetelne oceny. Przyczyni się to do rozwoju i doskonalenia polskich modeli językowych.