Dziś przychodzimy do Was z podsumowaniem roku działalności projektu Speakleash. 🚀
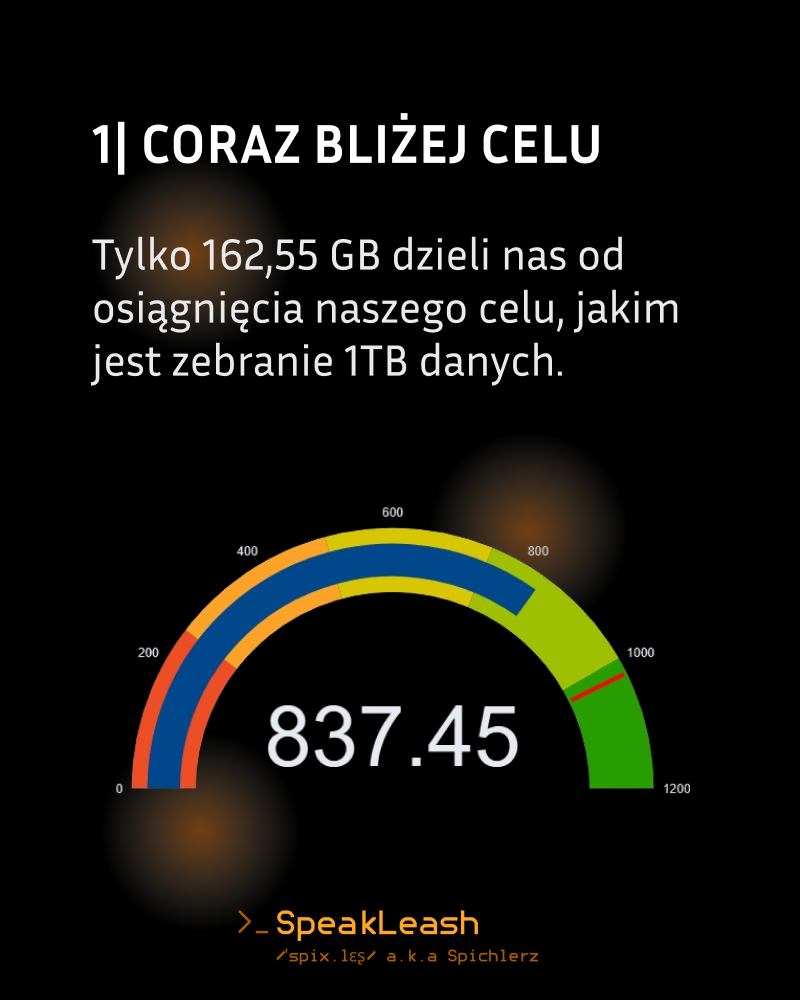
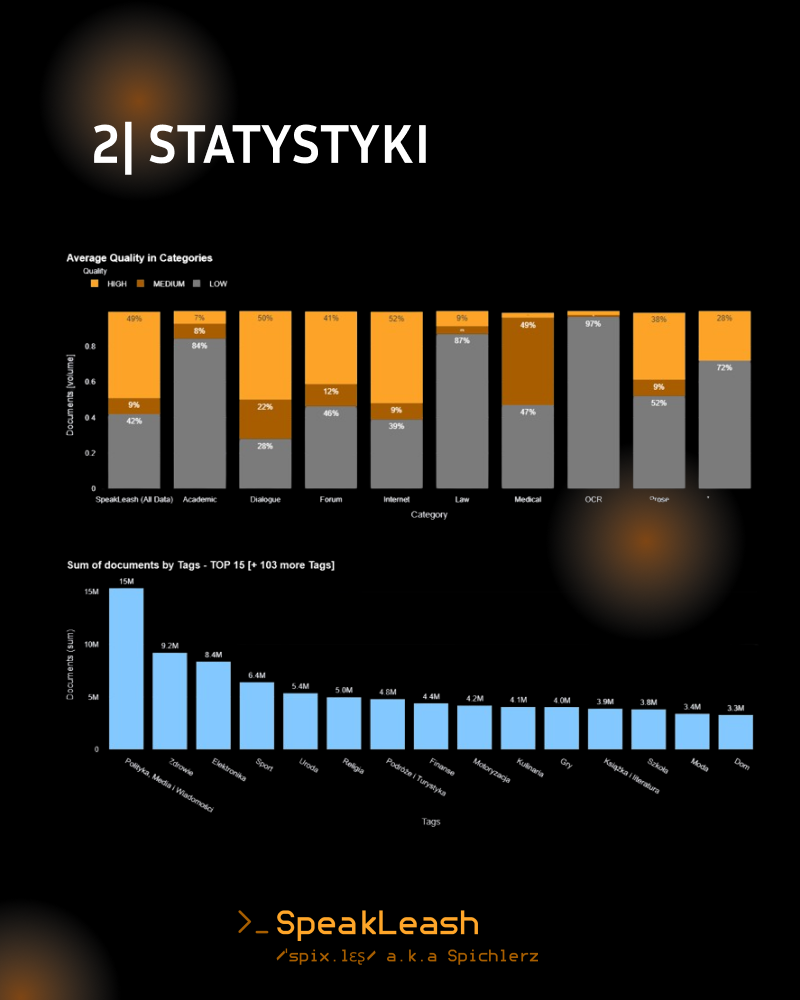
Kiedy ruszyliśmy z projektem nasz celu wydawał się bardzo odległy, niektórzy twierdzili, że wręcz niemożliwy. 🎯 Przez ten rok nie tylko sformalizowaliśmy naszą organizację jako fundację, ale przede wszystkim udało nam się zebrać aż 837,45 GBdanych, znaczy to, że jesteśmy już bardzo blisko docelowego 1TB! 💪 Warto zaznaczyć, że tworzymy w tym momencie największy na świecie (lub jeden z największych) zestawów danych tekstowych w jednym języku rozwijany w modelu open-science. Dodatkowo stawiamy nie tylko na ilość danych, ale też na ich jakość. Wszystkie zebrane przez nas dane są szczegółowo kategoryzowane i oceniane pod względem jakości, postępy naszych prac śledzić możecie na bieżąco na naszym dashboardzie. 🌐
Działalność Spichlerza to nie tylko zbieranie danych, ale też dzielenie się wiedzą i inspirowanie. 💡 W tym roku mieliśmy przyjemność wziąć udział w wielu konferencjach m.in. Data Science Summit oraz Data Science Summit Machine Learning Edition, dwóch edycjach Pytech Summit, konferencji jubileuszowej CLARIN-PL “Dziesięć lat otwartej infrastruktury naukowej CLARIN w Polsce” oraz Deviniti JIRA DAY Night Talk. 📣 Byliśmy partnerami wydarzeń takich jak ML in PL czy Hack To The Rescue. Gościliśmy w podcaście Nieliniowy Michal Dulemba, warto zaznaczyć, że odcinek z naszym udziałem określony został przez Crossweb.pl najpopularniejszym odcinkiem podcastu minionego roku. 🎙
Ten rok był bardzo ważny dla rozwoju AI w Polsce i rozpoczęcia prac nad PLLuM (Polish Large Language Universal Model). Nad tą inicjatywą pracują kluczowe jednostki zajmujące się AI w Polsce. Jesteśmy bardzo ciekawi efektów!
Nic z tego nie byłoby możliwe gdyby nie ciężka praca naszego zespołu, mieszanki kompetencji i charakterów. Do Discorda Speakleash (https://discord.gg/NN99d3Uv) dołączyło już ponad 160 osób i stale pojawiają się kolejne. 👥 Sebastian Kondracki, Maria Filipkowska, PhD, Krzysztof (Chris) Ociepa, Adrian Gwoździej, Paweł Kiszczak, Grzegorz Urbanowicz, Szymon Baczyński, Igor Ciuciura, Pawel Cyrta, Izabela Babis, Waldemar Boszko, Andrzej Cyboroń, Jacek Chwiła to tylko mała część naszego zespołu, nie sposób wymienić tutaj wszystkich.
Dziękujemy wszystkim zaangażowanym za waszą pracę i nie możemy się doczekać co przyniesie rok 2024! 🎉