Welcome to the premiere of the latest episode of the NIELINIOWY podcast on Youtube in which Michal Dulemba talks to the technical team of our project:
Maria Filipkowska, PhD, Jacek Chwiła, Adrian Gwoździej, Grzegorz Urbanowicz and Paweł Kiszczak.
https://lnkd.in/dESakTbb
Conversation on, among other topics:
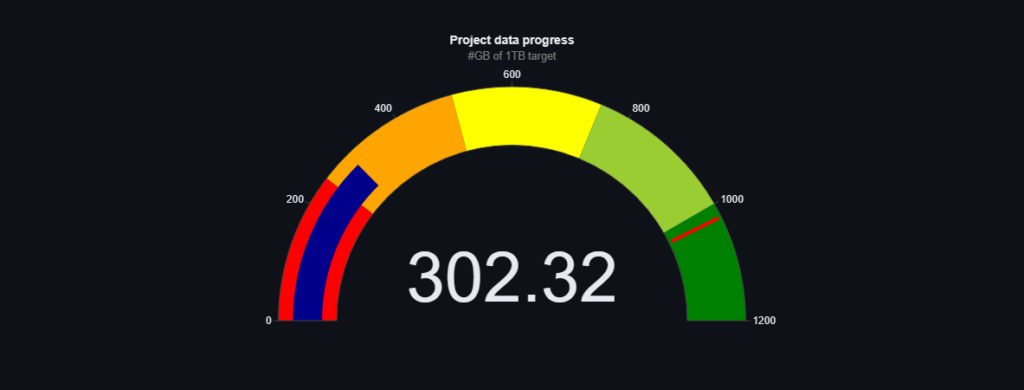
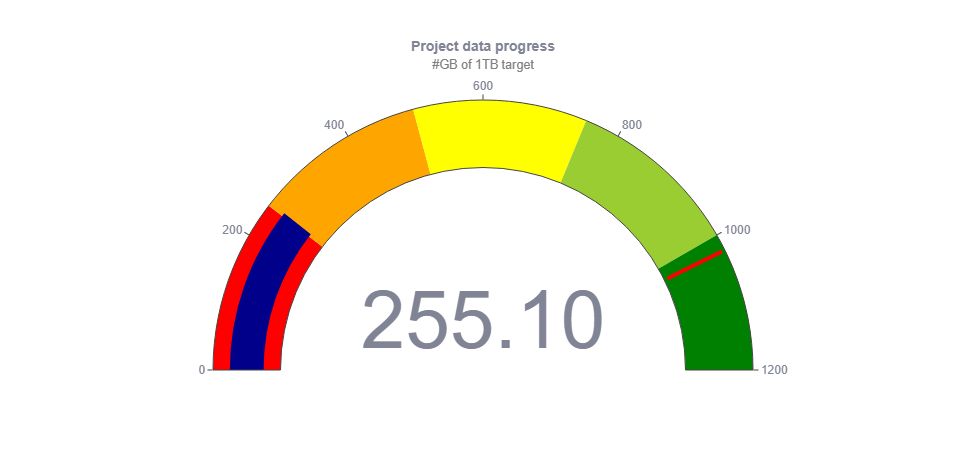
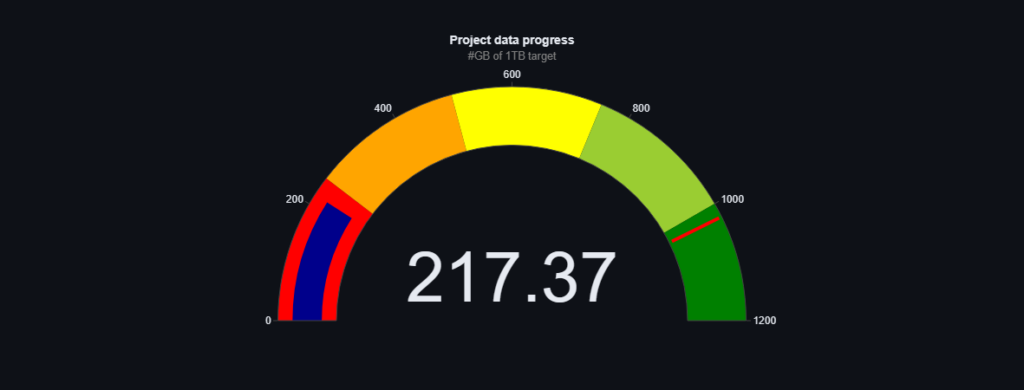
- how much data has already been collected
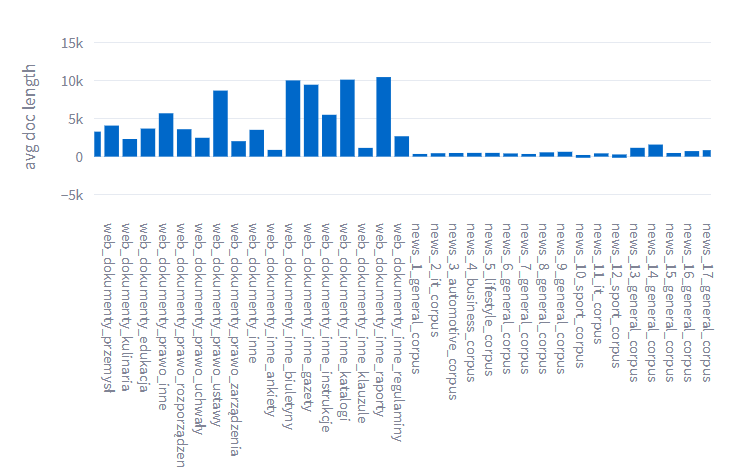
- variety of text data
- artificially generated text data
- kilometers of data in state archives
- the motivation of the team members
- the benefits of joining the Granary
- the variety of technical skills useful in the Granary
- the impact of Spichlerz on recruitment
- pride of working on a typically Polish project