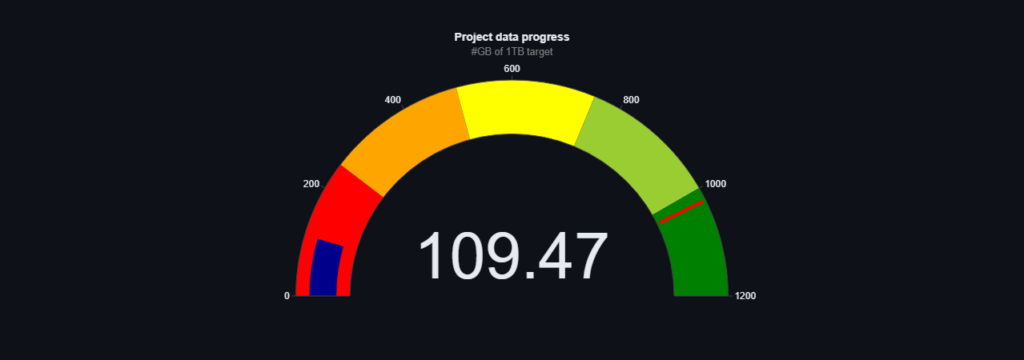
After months of research and talks we can say we made a milestone in our mission. We reached over 100GB of pure data text! It includes Wikipedia, thesis and novels. What do you think about it? What data would you like to add to train first polish GPT? Don’t hesitate to look it up here: https://speakleash.streamlit.app/.